Nature's model hobby kit - spliced genes (Part 1)
As a boy I used to love building miniature hobby aircraft. I loved the thrill of seeing the end-product slowly taking shape as I meticulously followed the assembly instructions. Every small plastic part had a role to play in the final scale model. At first - you had to carefully remove the small plastic parts from the molded frame, taking care not to damage any of the small pieces which were molded as part of one big sheet of plastic material. The plastic scaffolding held each of the places in place. It prevented them from getting lost, from falling out of the box, from being forgotten in the grand scheme of the assembly process. As each of the parts got its turn in the order prescribed on the building plans, I removed the pieces as they were required during assembly. The pieces differed greatly in size. Some made up large parts of the fuselage of the plane, others formed the wings, some played almost insignificant parts such as the radio antenna or were of average size such as the undercarriage. On their own, the parts were simply pieces of a big puzzle, but when I put all the small parts together they formed a tiny scale model of an airplane.
 |
| Model airplane depiction of how genes are packaged in the genome of eukaryotic including human genomes. |
When one considers the way that the information in our DNA encode many different important self assembling molecular protein machines. Each of them has a very significant part to play in making the final product function according to specification. Even a small defect in even the tiniest enzyme has serious health implications. Take for example the hormone Insulin. Hormones are tiny proteins. They act as biological messengers in our blood as part of the endocrine signalling system. Whereas neurons are the equivalent of peer-to-peer communication channels, hormones are more like messages on radio broadcast channels. They follow the blood to carry their signal to even the smallest capillary in our bodies.
The genetic recipe or gene that codes for Human Insulin is found on the negative DNA strand of Human Chromosome 11 at position chr11:2182015-2182439. The INS gene is a tiny gene, coding for a protein of only 110 amino acids in length. But, in spite of its small size code for an extremely important biological messenger directing all our cells when to take up sugar from our blood.
In order for a gene to be expressed as a protein, an important sequence of events needs to occur. Firstly, something needs to tell the machinery of the cell where to find the "source code" instructions on how to build Insulin. This is achieved by special proteins called transcription factors which recognizes and zooms in on the unique sequence of DNA letters before the transcription start site of a gene...the promoter sequence, which is sometimes also called the regulatory region or control panel of a gene. One such example is the TATA box which is bound by the TBP (Tata binding protein). This recruits other factors as well as the protein machine which transcribes or copies the gene transcript. Since the chromosomes never leave the nucleus, only the bases containing the gene in question is copied and exported from the nucleus into the cell cytoplasm where manufacturing takes place. In humans and other eukaryotic organisms, however, some "film editing" (gene splicing) first needs to take place on the "raw footage" (the primary transcript) before the messenger RNA (manufacturing documentary) can be exported from the nuclear pores.
That is what is depicted in the following figure. What you see is a block depiction of the DNA surrounding the INS gene (colored in light green). T's are black, A's are blue, G's are yellow and C's are orange. The gene is transcribed in the reverse direction since the gene is coded on the negative strand (running backwards towards the start of the chromosome).
The protein machine (RNA Polymerase), which is responsible for transcribing the DNA of the gene to messenger RNA, is oblivious to the fact whether it is transcribing parts which are exported from the nucleus (the exons - shown in light green blocks) or gene parts which are skipped (the intergenic sequences or introns). It does not even know when it moves across the future start codon (which is depicted in dark green) and the stop codon (depicted in red). Its job is simply to faithfully copy the gene into a message.
 |
| The INS Gene on chromosome 11 Start and stop codons indicated in green and red and 2 exons shown in light green. |
The "stop transcribing" signal that RNA Polymerase gets, which tells it that it has reached the end of the gene's region, is normally derived from a distinct region of secondary RNA structure formed by the RNA "sticking" to itself when the last part of the DNA is converted into RNA. This acts as a brake for the transcription process.
Another, totally independent, protein machine called the Spliceosome, which, like the Ribosome, also contains specified sequences of RNA joined to proteins, which helps it home-in on distinctive letter sequences in the unprocessed messenger RNA, that it uses to determine where the introns needs to be cut out of the RNA during the "film editing" process. In film one needs to accurately synchronize the audio and film and a trusted piece of slate clapboard used to be employed to accomplish this task. The clapping sound would provide the audio marker when the clapboard is closed on film. This simple means of synchronization, together with the date, the scene ("gene") and the take would provide the film editor with enough information to allow him to accurately join or "splice" the pieces of film together whilst also adding the audio track to the film.
 |
| Analogy to the sequence recognition of the Spliceosome |
As a boy I used to play with my father's 16-mm and 8-mm film equipment during school holidays. I would then use his splicing machine and splice together some old 8-mm movies from pieces of film I found lying around. You would lie the 2 ends neatly together in the splicing machine, which could also neatly cut the film ends, which you could then lay on top of each other after adding some clear "film cement" and permanently joining the "strands" of the film which would from then on survive the rigorous winding on my father's 8-mm film projector.
 |
| Film splicing machine - like the one I used for 8-mm film splicing is a good analogy to the spliceosome's breaking of the covalent bonds in the RNA backbone at the splice sites before rejoining the ends of the exons. |
The spliced "edited product" of the spliceosome is then called a mature messenger RNA molecule, which is exported into the cytoplasm to provide the assembly instructions to the ribosome machinery.

 |
| The Ribosome is the "protein printer" of the cell which works like an an old Empisal Automatic Knitting machine into which you could feed the instructions for knitting jumpers. The instructions were fed into the machine via a ribbon with holes which spacing and order contained the information. |
In quite a similar fashion, the 4 different RNA bases/nucleotides which forms part of the messenger RNA transcript are then used in groups of 3 letters at a time to provide 61 possible codons "code-words" in a code that is called "The Genetic Code". The code words from the genetic code is used to select one of a possible 20 amino acids and link them together in a linear chain to form a polypeptide.
Since there are 4 letters A,U (Uracil in RNA matching T in DNA),C,G, there are 4^3 = 64 possible code-words in this code. BUT, 3 of them do not have a matching "adapter" to pair them with an amino acid, which results in these 3 code words / codons resulting in a termination of the protein "knitting machine". These 3 codons which "code" for a STOP signal are: UAG, UGA and UAA. They act like the stop bits in a digital binary transmission or the STOP in a telegram.
When the Insulin gene is then translated by the Ribosome, it produces a protein which primary structure can be depicted as follows running from left to right:
 |
| Amino acid sequence of of human Insulin |
What I failed to mention is that every protein always starts with the amino acid Methionine(M) which is coded for by the DNA letters : ATG
The red letters indicates where the amino acids are which were coded for by DNA which lie close to the exon start positions of the original transcript.
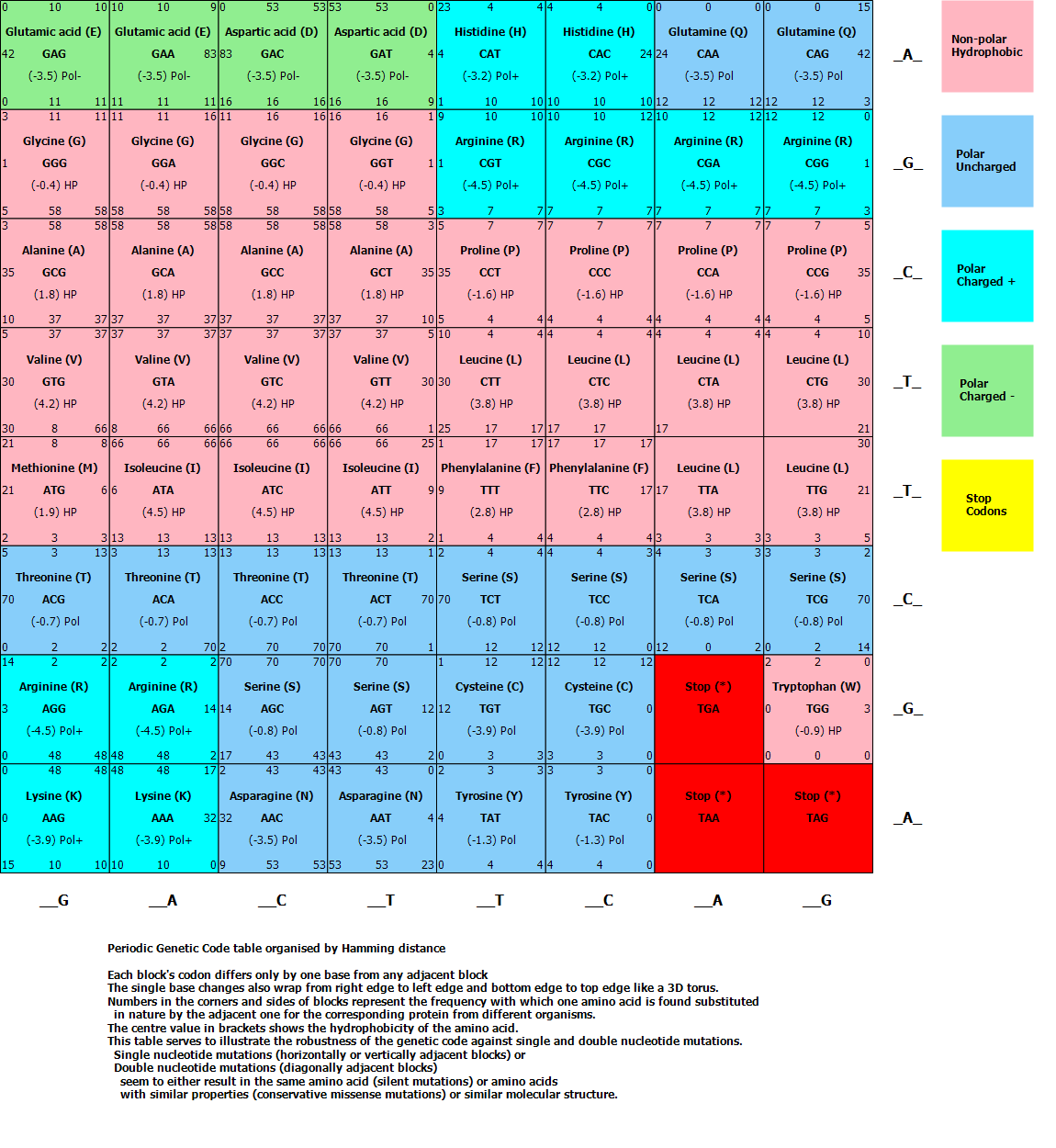
The Lookup table representing the Genetic Code used to find the appropriate amino acid for each of the 64 possible codons looks as follows:
I have arranged the amino acids similar to a periodic table of elements based on the hydrophobic or polar nature of the amino side chains. Codons are also arranged by shortest Hamming distance, meaning each codon differs only by one base from any adjacent codon, thus demonstrating the fine tuning of the genetic code to minimize errors in the protein chain due to single base/mis-sense mutations in the DNA.
It might not be widely known, but the Genetic Code can be proven to be "chosen" optimally for error minimization. As you can see from the Genetic Code table, when arranged by Hamming distance, is that when you move anywhere between codons by one position (representing a change in only 1 or 2 base mutations), the chances are good that the resulting new amino acid being coded has similar hydrophobic properties: meaning that the mutation does not change the folding of the resulting protein (which determines its function). Also notice that some mutations moving left or right does not even change the amino acid, but simply moves to another code-word coding for the same amino acid (a mutation that is known as a silent mutation.)
Please use this image only with permission as I have created it.
 As the amino acids are covalently joined like beads on a necklace, their water-"loving" (polar) and water-averse (hydrophobic/non-polar) side chains starts to interact with each other and with the watery environment in which they find themselves. Just like oil droplets form by hydrophobic molecules trying to "hide" from the water, the hydrophobic side chains tend to align themselves on the inside (or on the outside when in an oily membrane) whilst the polar side chains form secondary structures with each other via hydrogen bonds (which is the velcro equivalent in the molecular world). This spontaneous FOLDING of the protein then results in it "finding" its final shape, which determines its eventual function in the body. Mis-folded proteins cannot perform their intended functions and eventually gets destroyed by the protease machines in the cell.
As the amino acids are covalently joined like beads on a necklace, their water-"loving" (polar) and water-averse (hydrophobic/non-polar) side chains starts to interact with each other and with the watery environment in which they find themselves. Just like oil droplets form by hydrophobic molecules trying to "hide" from the water, the hydrophobic side chains tend to align themselves on the inside (or on the outside when in an oily membrane) whilst the polar side chains form secondary structures with each other via hydrogen bonds (which is the velcro equivalent in the molecular world). This spontaneous FOLDING of the protein then results in it "finding" its final shape, which determines its eventual function in the body. Mis-folded proteins cannot perform their intended functions and eventually gets destroyed by the protease machines in the cell.
The final end product of the Insulin (INS) gene is the Insulin hormone which is excreted from the cell (which in this case is the Islands of Langerhans in the human pancreas) and finds its way to its destinations which are the Insulin receptors on the surface of cells.
The Lookup table representing the Genetic Code used to find the appropriate amino acid for each of the 64 possible codons looks as follows:
I have arranged the amino acids similar to a periodic table of elements based on the hydrophobic or polar nature of the amino side chains. Codons are also arranged by shortest Hamming distance, meaning each codon differs only by one base from any adjacent codon, thus demonstrating the fine tuning of the genetic code to minimize errors in the protein chain due to single base/mis-sense mutations in the DNA.
It might not be widely known, but the Genetic Code can be proven to be "chosen" optimally for error minimization. As you can see from the Genetic Code table, when arranged by Hamming distance, is that when you move anywhere between codons by one position (representing a change in only 1 or 2 base mutations), the chances are good that the resulting new amino acid being coded has similar hydrophobic properties: meaning that the mutation does not change the folding of the resulting protein (which determines its function). Also notice that some mutations moving left or right does not even change the amino acid, but simply moves to another code-word coding for the same amino acid (a mutation that is known as a silent mutation.)
Please use this image only with permission as I have created it.

The final end product of the Insulin (INS) gene is the Insulin hormone which is excreted from the cell (which in this case is the Islands of Langerhans in the human pancreas) and finds its way to its destinations which are the Insulin receptors on the surface of cells.
 |
| In the figure you can see a protein complex of the Insulin protein produced after its folded state is reached. |
I love proteins.
No comments:
Post a Comment
Please leave me a comment